Large-scale Deployments
If you want to deploy agents across a large-scale environment, your deployment strategy must ensure that all agents are continuously active and stay connected to Tenable Vulnerability Management or Tenable Nessus Manager.
Note: In addition to these deployment considerations, Tenable recommends reviewing the Tenable Nessus Agent General Best Practices
Deployment Strategy
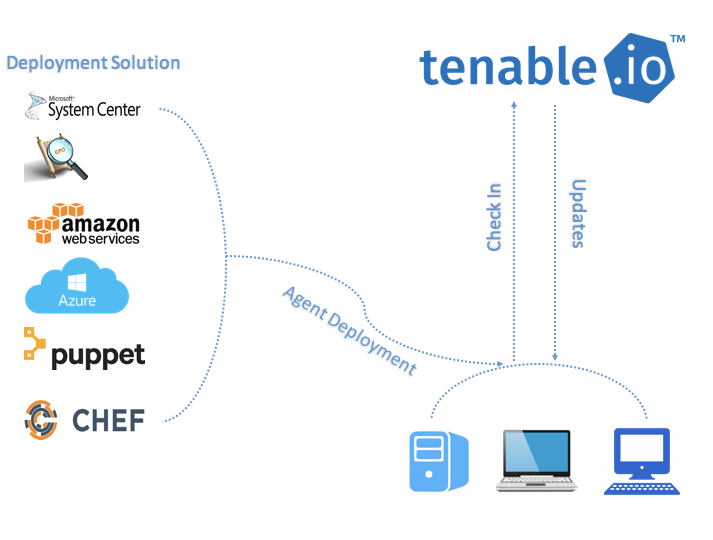
When deploying many agents, consider using software to push agents through the network. For example:
Tenable recommends that you deploy batches of agents over a 24-hour period when deploying a large number of agents. This is especially helpful if you have a limited network bandwidth and need to limit the amount of data your network is downloading at one time.
After you install an agent, it receives its first plugin update once it receives instructions to run an assessment. The agent sets a timer to attempt the next update 24 hours from the initial plugin update time (and update the plugin update date on subsequent successful plugin downloads). Deploying your agents in batches also prevents too many agents from checking for product updates at one time and consuming too much bandwidth.
An agent links to Tenable Nessus Manager or Tenable Vulnerability Management after a random delay ranging from zero to five minutes. This delay occurs when the agent initially links, and also when the agent restarts either manually or through a system reboot. Enforcing a delay reduces network traffic when deploying or restarting large amounts of agents, and reduces the load on Tenable Nessus Manager or Tenable Vulnerability Management.
Clustering
With Tenable Nessus Manager clustering, you can deploy and manage large numbers of agents from a single Tenable Nessus Manager instance. For Tenable Security Center users with over 10,000 agents and up to 200,000 agents, you can manage your agent scans from a single Tenable Nessus Manager cluster, rather than needing to link multiple instances of Tenable Nessus Manager to Tenable Security Center.
A Tenable Nessus Manager instance with clustering enabled acts as a parent node to child nodes, each of which manage a smaller number of agents. Once a Tenable Nessus Manager instance becomes a parent node, it no longer manages agents directly. Instead, it acts as a single point of access where you can manage scan policies and schedules for all the agents across the child nodes. With clustering, you can scale your deployment size more easily than if you had to manage several different Tenable Nessus Manager instances separately.
Example scenario: Deploying 100,000 agents
You are a Tenable Security Center user who wants to deploy 100,000 agents, managed by Tenable Nessus Manager.
Without clustering, you deploy 10 Tenable Nessus Manager instances, each supporting 10,000 agents. You must manually manage each Tenable Nessus Manager instance separately, such as setting agent scan policies and schedules, and updating your software versions. You must separately link each Tenable Nessus Manager instance to Tenable Security Center.
With clustering, you use one Tenable Nessus Manager instance to manage 100,000 agents. You enable clustering on Tenable Nessus Manager, which turns it into a parent node, a management point for child nodes. You link 10 child nodes, each of which manages around 10,000 agents. You can either link new agents or migrate existing agents to the cluster. The child nodes receive agent scan policy, schedule, and plugin and software updates from the parent node. You link only the Tenable Nessus Manager parent node to Tenable Security Center.
For more information, see Clustering in the Tenable Nessus User Guide.
Agent Groups
Tenable recommends that you size agent groups appropriately, particularly if you are managing scans in Tenable Nessus Manager or Tenable Vulnerability Management and then importing the scan data into Tenable Security Center. You can size agent groups when you manage agents in Tenable Nessus Manager or Tenable Vulnerability Management.
The more agents that you scan and include in a single agent group, the more data that the manager must process in a single batch. The size of the agent group determines the size of the .nessus file that must be imported into Tenable Security Center. The .nessus file size affects hard drive space and bandwidth.
Group Sizing
| Product | Agents Assigned per Group |
|---|---|
| Tenable Vulnerability Management |
Unlimited agents per group if not sending to Tenable Security Center 20,000 agents per group if sending to Tenable Security Center |
| Tenable Nessus Manager |
Unlimited agents per group if not sending to Tenable Security Center 20,000 agents per group if sending to Tenable Security Center |
| Tenable Nessus Manager Clusters | Unlimited since scans are automatically broken up as appropriate by separate child nodes. |
Group Types
Before you deploy agents to your environment, create groups based on your scanning strategy.
The following are example group types:
Operating System

Asset Type or Location

You can also add agents to more than one group if you have multiple scanning strategies.

Scan Profile Strategy
Once you deploy agents to all necessary assets, you can create scan profiles and tie them to existing agent groups. The following section describes a few scan strategies.
Operating System Scan strategy
The following strategy is useful if your scanning strategy is based off of the operating system of an asset.

Basic Agent Scan - Linux
In this example, a scan is created based on the Basic Agent Scan template, and is assigned the group Amazon Linux, CentOS, and Red Hat. This scan only scans these assets.

Asset Type or Location Scan Strategy
The following strategy is useful if your scanning strategy is based off of the asset type or location of an asset.

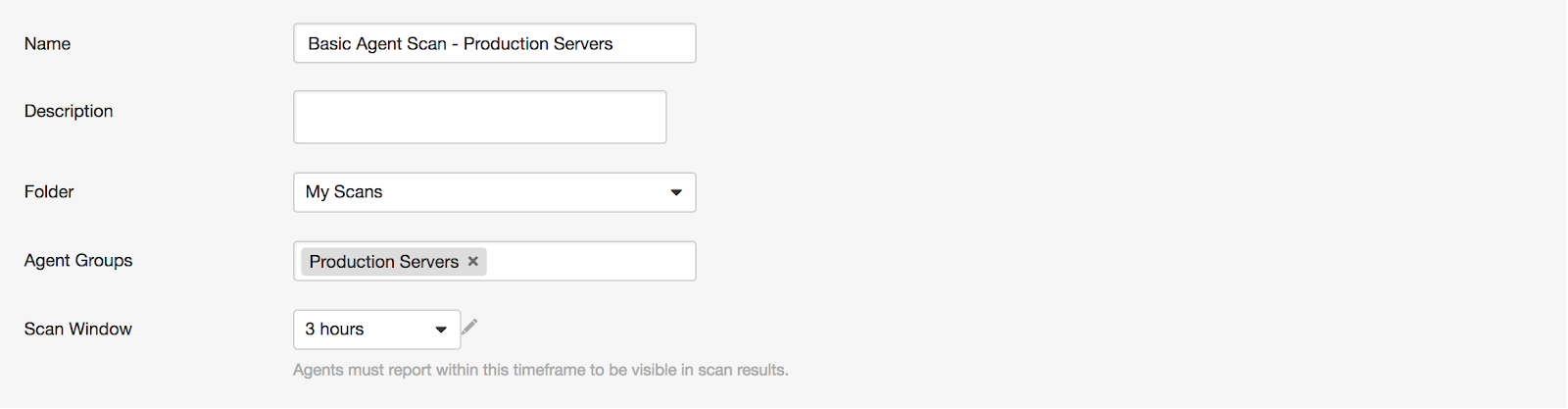
Basic Agent Scan - Production Servers
In this example, a scan is created a scan based on the Basic Agent Scan template, and is assigned the group Production Servers. This scan only scans production server assets.
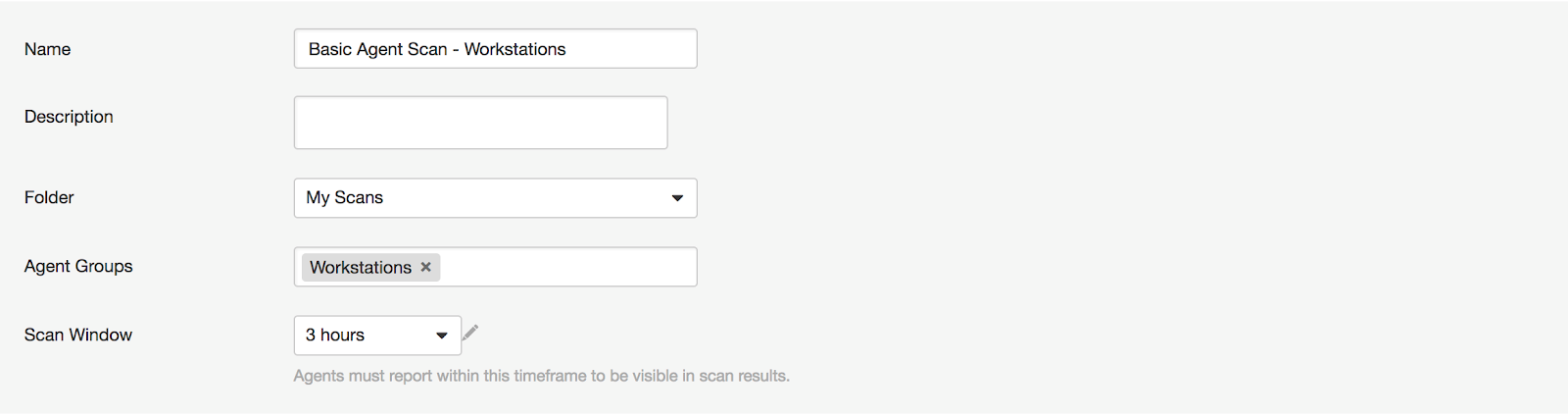
Basic Agent Scan - Workstations
In this example, a scan is created based on the Basic Agent Scan template, and is assigned the group Workstations. This scan only scans workstation assets.
Scan Staggering
While scans with the Tenable Nessus Agents are more efficient in many ways than network scans, scan staggering is something to consider on certain types of systems.
For example, if you install Tenable Nessus Agents on virtual machines, you may want to distribute agents among several groups and have their associated scan windows start at slightly different times.
Staggering scans limits the one-time load on the virtual host server, because agents run their assessments as soon as possible at the start of the scan window. Oversubscribed or resource-limited virtual environments may experience performance issues if agent assessments start on all systems at the same time.